NR. 105 Sie entwickeln eine Lösung mit einer Lambda-Architektur auf Microsoft Azure.
Die Daten auf der Testebene müssen die folgenden Anforderungen erfüllen:
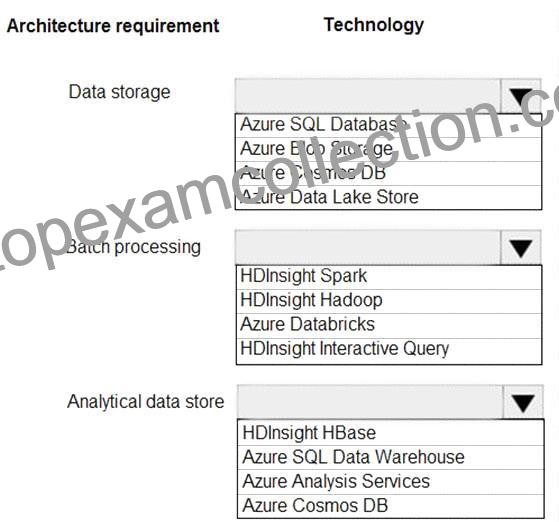
Speicherung von Daten:
* als Speicherort dienen (oder große Mengen großer Dateien in verschiedenen Formaten).
*Implementierung eines optimierten Speichers für Big-Data-Analyse-Workloads.
*Stellen Sie sicher, dass die Daten in einer hierarchischen Struktur organisiert werden können.
Stapelverarbeitung:
*Verwenden Sie eine verwaltete Lösung für die speicherinterne Verarbeitung von Berechnungen.
*Die Programmiersprachen Scala, Python und R werden unterstützt.
*Bieten Sie die Möglichkeit, die Größe des Clusters automatisch zu ändern und ihn zu beenden.
Analytischer Datenspeicher:
*Unterstützung der Parallelverarbeitung.
*Spaltenweise Speicherung verwenden.
*Unterstützung von SQL-basierten Sprachen.
Sie müssen die richtigen Technologien für den Aufbau der Lambda-Architektur ermitteln.
Welche Technologien sollten Sie verwenden? Wählen Sie die entsprechenden Optionen im Antwortbereich aus. HINWEIS: Jede richtige Auswahl ist einen Punkt wert.
Erläuterung
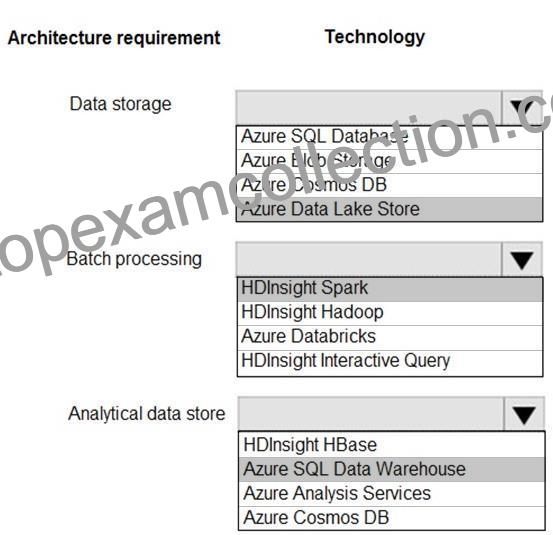
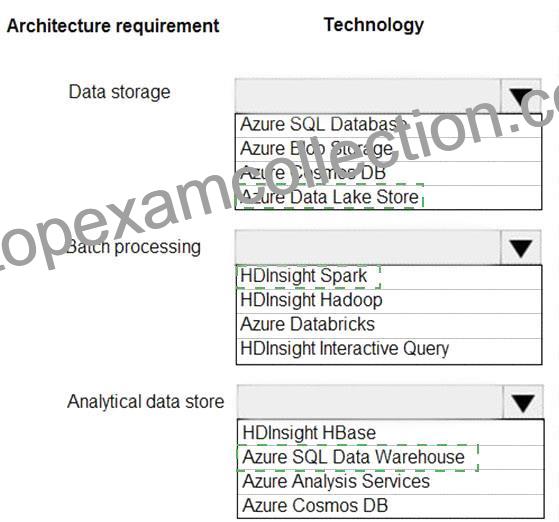
Datenspeicherung: Azure Data Lake Store
Ein Schlüsselmechanismus, der es Azure Data Lake Storage Gen2 ermöglicht, Dateisystemleistung in Objektspeichergröße und -preisen zu bieten, ist die Hinzufügung eines hierarchischen Namensraums. Dadurch kann die Sammlung von Objekten/Dateien innerhalb eines Kontos in einer Hierarchie von Verzeichnissen und verschachtelten Unterverzeichnissen organisiert werden, so wie das Dateisystem auf Ihrem Computer organisiert ist. Wenn der hierarchische Namensraum aktiviert ist, kann ein Speicherkonto die Skalierbarkeit und Kosteneffizienz eines Objektspeichers mit einer Dateisystem-Semantik bieten, die den Analysemaschinen und Frameworks vertraut ist.
Stapelverarbeitung: HD Insight Spark
Aparch Spark ist ein Open-Source-Framework für die parallele Verarbeitung, das die In-Memory-Verarbeitung unterstützt, um die Leistung von Big-Data-Analyseanwendungen zu steigern.
HDInsight ist ein verwalteter Hadoop-Dienst. Mit ihm können Sie Hadoop-Cluster in Azure bereitstellen und verwalten. Für die Stapelverarbeitung können Sie Spark, Hive, Hive LLAP und MapReduce verwenden.
Sprachen: R, Python, Java, Scala, SQL
Analytischer Datenspeicher: SQL Data Warehouse
SQL Data Warehouse ist ein Cloud-basiertes Enterprise Data Warehouse (EDW), das Massively Parallel Processing (MPP) verwendet.
SQL Data Warehouse speichert Daten in relationalen Tabellen mit spaltenweiser Speicherung.
Referenzen:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-overview-what-is






